发布时间: 2020年2月10日
上周,Kaggle宣布了一项新挑战。不同的挑战-在许多方面。它基于抽象和推理语料库,并附有Francois Chollet最近的论文。 在这项工作中,Chollet强调了当前AI研究议程的一些缺点,并主张对智能系统进行基于心理和能力的评估,从而实现标准化和可靠的比较。更重要的是,它引入了可行的以先验,经验和归纳难度为基础的类人通用智能的定义。研究社区可以使用此定义来衡量进度并共同致力于一个共同的目标。阅读本文之后,在我们的阅读小组中进行讨论(您可以在此处查看Heiner Spiess的演讲),并且重新阅读我的思想仍在整理知识内容。因此,请坚持并让我给您一个关于64页金矿的总结。我还对抽象和推理语料库基准进行了一些探讨,因此,如果您想着手处理智能,请坚持学习!
问题:找到智能的精确定义
机器学习研究的进展绝对不是在寻找下一个性感技能或游戏。但是通常感觉就像是。DeepBlue,AlphaGo,OpenAI的Five,AlphaStar都是大规模公关活动的例子,这些公关活动仅在其“成功”声明发布后不久就因缺乏通用性而受到批评。每当“技巧球”被推向下一个挑战性游戏时(也许哈纳比(Hanabi)可以进行一些心理理论上的多主体合作学习?)。但是,我们到哪里去呢?解决每个游戏的单独算法不一定会推广到更广泛的类人挑战。游戏只是人为的一个子集,并不代表我们物种生态位的全部范围(可以快速生成数据)。综上所述:智力不仅仅是学习技能的集合。因此,AI研究界必须解决一个共同的目标-智力的一致目标定义。
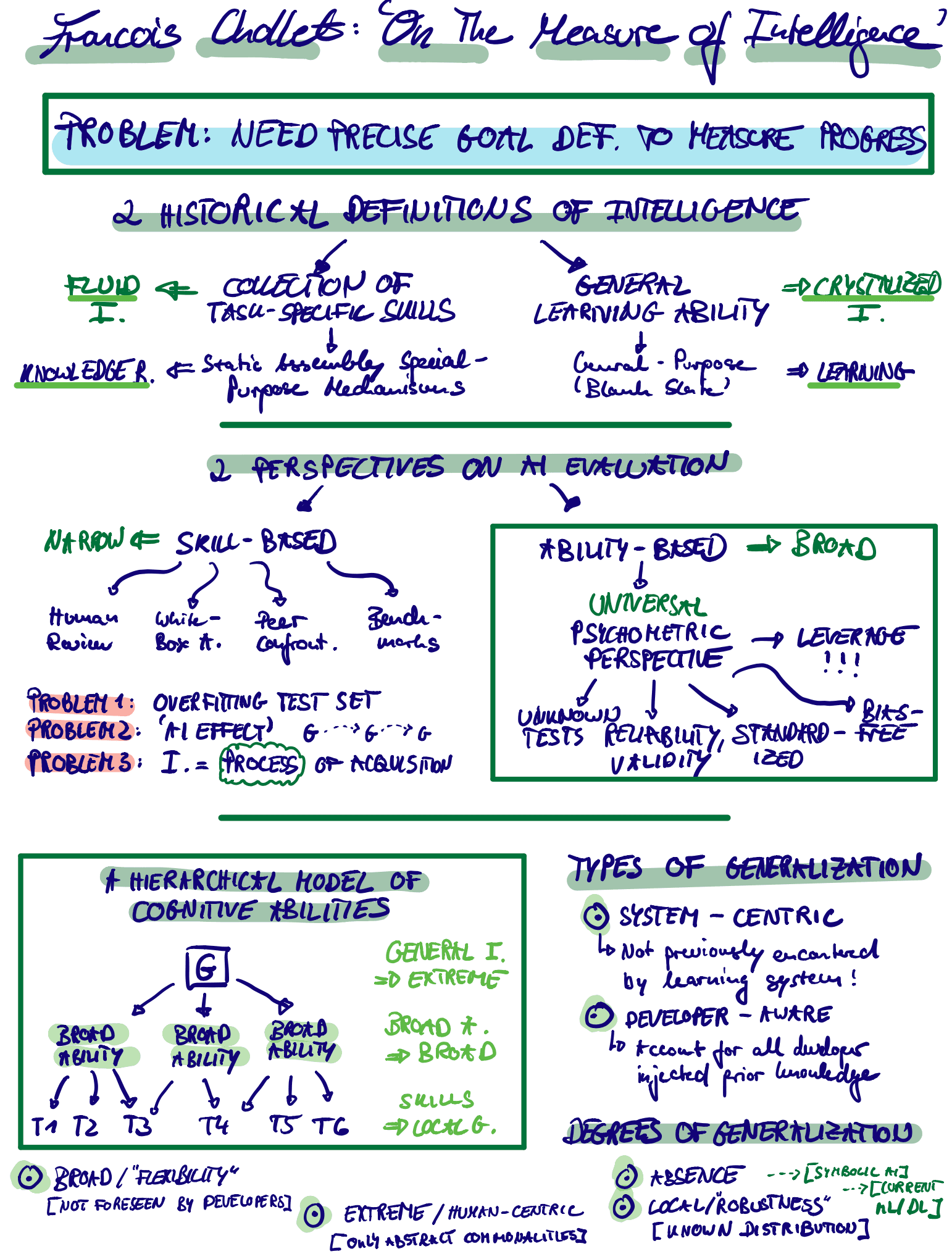
从历史上看,已经有很多尝试来测量智力-或多或少地重叠。Chollet的论文首先回顾了两个主要支柱:基于技能的智力评估与基于能力的智力评估。他认为,虽然技能是智能系统的关键输出,但它们仅是人造物。另一方面,能力允许扩大可能的技能输出的空间。通过学习的魔力(例如,基于进化/梯度,基于可塑性,基于神经动力学),智能系统能够将先前的知识和经验与新的情况相结合。这种适应性强,面向任务且非常有条件的过程最终可能会导致智能问题。
在我看来,很明显,学习和与生境相关的归纳性偏见(例如我们的身体和神经系统)的出现必定是智力的核心。它弥合了所有时间尺度,并与Jeff Clune,David Ha和Blaise Aguera在NeurIPS 2019期间提出的想法产生了共鸣。我们的机器学习基准也应该反映出这一高级目标。这并不是说已经有很多尝试,包括以下内容:
- 元学习:我们不应该优化在2亿个ATARI游戏框架上受过训练的特工的绩效,而应着眼于快速适应性和灵活性,以解决特定任务所需的技能。元学习明确地将快速适应性表述为外循环目标,而内循环则被限制为只能在SGD的几次更新内学习或展开循环动力学。
- 关系深度学习和图神经网络:关系方法将深度学习与围绕命题逻辑的传统方法结合在一起。因此,人们可以“理解”表示如何相互比较,并获得一组可解释的关注头。希望这样的推断/学习的关系表示可以轻松地跨任务转移。
- 课程学习:另一种方法是建立有效的任务序列,以使学习者能够平稳地跨过不断变化的损失面。这样做需要任务之间有重叠,这样才能进行技能转移。直觉上,这很像我们通过不断挑战而获得的技能。
尽管如此,大多数社区仍在研究可比较的利基问题,这些问题远离泛化和类似人类的一般智慧。那么我们该怎么办?
迈向智力的心理计量学


AI和ML社区一直在梦想一个前所未有的通用智能概念。人类的认知和大脑是自然的第一个起点。但是神经科学方面的发现似乎很缓慢/模棱两可,而且如何将低水平的细胞灵感转化为归纳性偏见的算法形式并不常见。![]() 另一方面,心理学和心理计量学是心理测量的学科(根据Wikipedia ),可提供不同层次分析的见解。Chollet建议不要再忽视来自数十年来开发人类智能测试的社区的见解。
另一方面,心理学和心理计量学是心理测量的学科(根据Wikipedia ),可提供不同层次分析的见解。Chollet建议不要再忽视来自数十年来开发人类智能测试的社区的见解。
他的主要论据之一是反对普遍的g因子。相反,所有已知的智能系统都取决于其环境和任务规范。人类智能针对人类问题进行了优化。因此,在解决火星可能遇到的问题方面表现更差。这就是所谓的“无免费午餐智力定理”。因此,我们对智力的所有定义也仅在人类参考框架内有效。我们不应该忽略对人类的拟人化但可行的评估,而应该接受它。心理学的角度可以使我们清楚地了解开发人员的偏见以及我们在人工系统中建立的先验知识。乔莱特建议发展以人为中心的智力测验,结合了人类认知先验和核心知识的发展心理学概念。这些包括不同级别的描述(例如低级的感觉运动反射,学习如何学习的能力以及高级知识)以及先天的能力(例如基本几何,算术,物理和代理)。因此,可行的智能定义如下:
“系统的智能是衡量其在一定范围内与先验,经验和归纳难度有关的任务中技能获取效率的指标。” -乔莱特(2019;第27页)
此外,Chollet还提供了基于形式化算法信息论的人工系统智能度量:

换句话说:智力的度量可以解释为当前信息状态与在不确定的未来中表现良好的能力之间的转换率。它说明了任务的一般化难度,先验知识和经验,并允许对任务进行主观加权以及我们关注的任务的主观构造。该措施与所提出的任务范围(生态位)相关联,将技能仅视为输出工件属性,并基于课程优化。从总体上讲,此度量可用于定义自上而下的优化目标。这将允许应用一些连锁规则/自动区分魔术(如果生活可以平滑区分),最重要的是量化进度。
显而易见的下一个问题变成了:那么,我们如何才能实际采取这种措施?
新基准:抽象和推理语料库(ARC)

抽象和推理语料库通过引入一个新颖的基准来解决这个问题,该基准旨在评估和提供可重复的人工智能测试。它使人想起了经典Raven的渐进矩阵,甚至对于不时的人类来说也非常棘手。每个任务(请参见上面的示例)为系统提供一组示例输入输出对,并在输出中查询测试输入。该系统最多可以提交3个解决方案,并接收二进制奖励信号(真/假)。上述任务的具体解决方案需要对重力概念有一个大概的了解。输出只是将对象“拖放”到图像阵列的底部。但这只是一个解决方案示例。基准范围更广,需要不同的核心知识概念。整个数据集包括400个训练任务,400个评估任务和另外200个保持测试任务。非常令人兴奋,对吧?
在过去的几天里,我对基准测试有点不满。尝试使用即插即用的深度(强化)学习时,存在几个基本问题。最初,问题在于不规则的输入/输出形状。如果您训练自己喜欢的MNIST-CNN,则输入层和输出层的形状都是固定的(即32×32和10个输出数字标签)。从这个意义上说,ARC基准不是常规的。有时有两个形状不同的示例,而输出查询的确有不同的示例。因此,变得不可能训练具有单个输入/输出层的网络。此外,示例数也有所不同(请参见下图),目前尚不清楚如何利用这3次尝试。我最初的想法围绕在给定的示例上进行k折交叉验证形式,并尝试利用Relational DL社区(例如PrediNet)的想法。训练两个,然后测试最后一个示例。仅在收敛和交叉验证为零之后,我们才进行实际测试。主要问题:每个示例的在线培训。这可能变得非常计算密集。

尝试尝试的一种可能方式可能是元强化学习目标的形式。这可以允许快速适应。因此,我们将在与Oracle的3个闭环交互中优化性能。这也可以通过训练RL ^ 2 LSTM来完成,后者接收先前的尝试反馈作为输入。以下是一些进一步的挑战见解:
- 必须进行适应性或程序综合性的针对特定任务的培训。仅将所有先验硬编码到简单的前馈网络中是不够的。
- 当我们作为人类查看输入-输出对时,我们会立即找出正确的先验条件,以即时解决测试示例。这包括定义解决方案空间的调色板。如果火车输出具有三种类型的唯一数字像素值,则测试输出不太可能具有20。
- 我意识到,当我尝试解决其中一项任务时,我会进行很多跨任务推理。仔细检查假设并执行基于模型的交叉验证。将推理作为重复的假设检验进行构架可能是一个不错的主意。
- 从根本上限制最小化逐像素MSE损失。由于解决方案的评估没有半点错误,即使很小的MSE损失也将导致错误的输出。
- 核心知识很难编码。关系深度学习和几何深度学习提供了令人鼓舞的观点,但仍处于起步阶段。我们远不能通过元学习来模仿进化。
- 尝试解决所有问题的目标过于雄心勃勃(目前而言)。
乔莱特本人建议潜入一个名为“程序综合”的领域。直观地讲,这要求您生成程序以自己解决一些任务,然后在更高级别上学习此类程序。https://platform.twitter.com/embed/index.html?dnt=false&embedId=twitter-widget-0&frame=false&hideCard=false&hideThread=false&id=1228056479854317568&lang=en&origin=https%3A%2F%2Froberttlange.github.io%2Fposts%2F2020%2F02%2Fon-the-measure-of-intelligence%2F&siteScreenName=RobertTLange&theme=light&widgetsVersion=ed20a2b%3A1601588405575&width=500px
所有这些想法仍然留下了一个问题,即对于哪种归纳偏见应稍加开放:用于视觉处理的卷积,用于集合操作的注意力,用于记忆的RNN以及与遮挡/物体持久性作斗争?我为有兴趣开始使用基准测试的每个人草拟了一个小笔记本。你可以在这里找到它。在这里,您可以找到一个kaggle内核,该内核为ARC中的10个任务提供“手动”解决方案程序。
一些结论性思想
我真的很喜欢Geoffrey Hinton的这句话:
“未来取决于某些研究生,他们对我所说的一切深表怀疑。”
即使无处不在的反向传播和深度学习的重大突破,这也表达了严重的怀疑。在过去的几天里,我的经历非常谦虚,使很多事情都得到了体现。我喜欢被最近的进展所炒作,但是在ML社区面前也面临着巨大的挑战。当前形式的深度学习绝对不是智能的圣杯。它缺乏灵活性,效率和分布外性能。智能系统还有很长的路要走。ARC基准测试提供了一条很好的途径。因此,让我们开始吧。![]()
PS:挑战进行了3个月。

{kind=link}
Leave a comment