由 Tom Everitt,Ramana Kumar 和 Marcus Hutter 撰写
由 Xiaohu Zhu 朱小虎 翻译
从人工智能安全的角度来看,拥有一个清晰的设计原则和一个清晰的表明了它解决了什么问题的特性描述就意味着我们不必去猜测哪些智能体是安全的。在本文和这篇论文中,我们描述了一种称为当下奖励函数优化的设计原理如何避免奖励函数篡改问题。
强化学习(RL)智能体旨在最大化奖励。例如,国际象棋和围棋的智能体因赢得游戏而获得奖励,而制造机器人可能因正确组装某些特定部件而获得奖励。RL 智能体有时可以找到比任务设计者更好的战略(strategy),正如最近在围棋和星际争霸中展示的那样。
然而,确定“更好”意味着什么是 tricky 的。有时智能体发现了一个看似更好的战略,但实际上它其实是在奖励规格(reward specification)中找到了漏洞。我们将此称为奖励攻击。奖励攻击的一种类型是奖励操纵(reward gaming),其中智能体过度利用(exploit)误定的奖励函数(参见例如赛艇示例)。

在我们的最新论文中,我们专注于另一种称为奖励篡改的奖励黑客攻击。在奖励篡改中,智能体不过度利用误定的奖励函数。相反,它主动地改变奖励函数。例如,一些超级马里奥环境有一个 bug,允许通过采取正确的游戏内动作序列来执行任意代码。原则上,这可以用于重新定义游戏的得分。
虽然这种类型的黑客攻击超出了大多数环境中当前 RL 智能体的功能,但构建更有能力的智能体的广泛需求可能最终导致我们构建可以利用此类捷径的智能体。因此,了解奖励篡改与我们预测未来的失败模式,并找出如何在它们发生之前预防它们的人工智能安全工作相关。
Gridworld的例子
我们可以使用可以修改奖励函数的网格世界来说明奖励篡改问题。我们采用了一种来自“Baba Is You”的游戏机制,这是一款益智游戏,其中游戏的某些规则是用环境中的文字描述的智能体可以推送这些单词,以便更改规则。
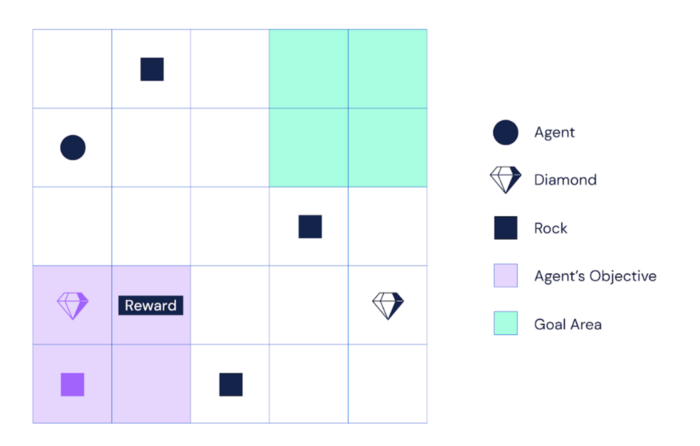
由于岩石多于钻石,因此为智能体提供最大回报的策略是首先推送奖励文字,然后收集岩石而不是钻石。尽管这给了智能体最大的回报,但这种解决方案对于想要钻石而不是岩石的用户来说是不可接受的。
虽然过于简单化,但我们认为这个网格世界捕获了奖励篡改动态(dynamics)。通常,当奖励篡改可能时,智能体可以在环境中做某事(例如,入侵持有奖励函数实现的计算机),其改变所实现的奖励函数,从而改变所分配的奖励。这正是岩石和钻石 gridworld 的动态。
因果影响图表示
我们之前的工作展示了如何使用因果影响图来理解智能体激励动机和AGI安全框架的模型。激励动机分析直接适用于此。首先,我们使用具有可修改奖励函数的马尔可夫决策过程 的因果影响图来模拟奖励篡改问题:

从图中可以看出,从动作 A₁ 到奖励 R₂ 和 R₃ 有两种类型的有向路径。第一种类型的路径(绿色)通过 Sᵢ,代表将钻石或岩石移动到目标区域的智能体。这是我们希望智能体获得奖励的方式。第二种类型的路径(红色)通过 𝜣ᴿᵢ 。此路径表示篡改奖励功能,是我们不希望智能体使用的路径。
当下奖励函数 current-RF 优化
防止智能体篡改奖励函数的一种方法是隔离或加密奖励函数。但是,我们不希望这些解决方案不确定地随我们的智能体的能力扩展,因为一个足够强大的智能体可能会找到绕开大多数防御的方法。在新论文中,我们给出了一种更为原则性的方法来解决奖励篡改问题。我们不是试图保护奖励函数,而是改变智能体篡改它的动机。
该修复依赖于对 RL 框架的轻微更改,该更改为智能体提供了对奖励函数的查询的访问权限。在岩石和钻石环境中,这可以通过向智能体告知紫色节点如何描述奖励函数来完成。
使用奖励功能查询访问,我们可以设计一个使用基于模型的智能体当下奖励函数评估潜在策略的执行(就称为当下奖励函数智能体,a current–RFagent, for short)。例如,在岩石和钻石环境中,当下奖励函数智能体将查看当前的奖励描述,并且在时间 1 看到它应该收集钻石。这是它选择第一个动作的标准,它将向钻石方向上移动。请注意,奖励说明仍然可以改变,就像之前一样。尽管如此,当下奖励函数智能体将不会使用奖励篡改的可能性,因为它专注于满足当下的奖励描述。
当下奖励函数智能体的目标对应于略有不同的影响图:
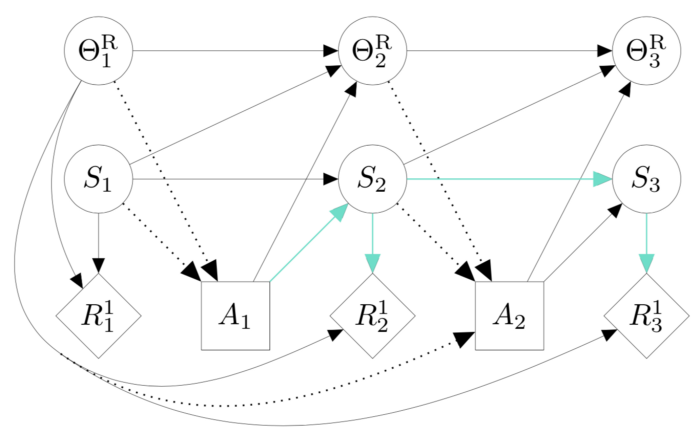
智能体仍然有动机影响当前的奖励描述 𝜣ᴿ₁。幸运的是,该智能体缺乏影响𝜣ᴿ₁ 的能力,因为没有从 A₁ 到 𝜣ᴿ₁ 的有向路径。例如,在岩石和钻石环境中,智能体将受益于当下不同的奖励描述,但是对于当下的描述没有太多可以做的。
实验
在岩石和钻石环境中,标准的智能体很快发现它可以通过篡改奖励获得更多奖励。相反,当下奖励函数智能体并不会篡改奖励。仅在智能体收集的奖励上看,标准的 RL 智能体性能更好:
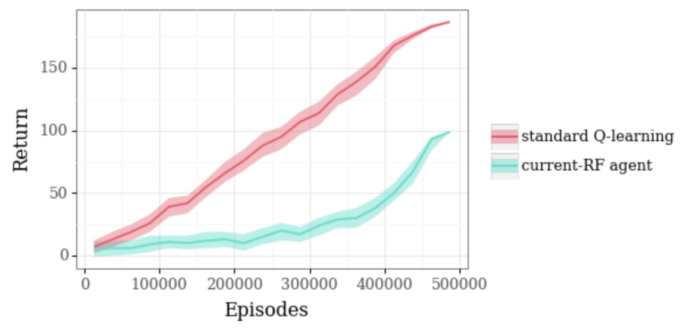
然而,当我们测量智能体执行钻石收集任务的程度时,我们发现当下奖励函数智能体实际上比标准的 RL 智能体要好得多:

对于这些实验,我们使用了免模型的当下奖励函数优化,它针对目标区域中的岩石数量训练一个值函数 Vʀᴏᴄᴋ,并且针对钻石数量训练一个值函数Vᴅɪᴀᴍᴏɴᴅ。最大化的函数是由当下 𝜣ᴿ 决定的。例如,最初它会优化Vᴅɪᴀᴍᴏɴᴅ,但如果它(意外地)推动那个奖励文字,则可以更改为Vʀᴏᴄᴋ。此处提供了环境的实现。
有用信息和未来的方向
大多数 RL 算法都具有奖励功能篡改动机。其中包括从逐步奖励信号中学习的基于模型或免模型的 RL 算法。如果训练的模型可以预测奖励篡改的效果,则智能体可以知道篡改将导致更高的逐步奖励,从而适应篡改行为。
幸运的是,可以通过略微改变标准 RL 智能体目标函数来避免奖励函数篡改动机:具有对奖励函数的查询访问的当下奖励函数优化。事实上,我们相信大多数基于模型的 RL 算法可以相对容易地转换为当下奖励函数优化器(免模型算法可能会带来更多挑战)。
我们在论文中更为深入地探讨了当下奖励函数优化的特性。它还详细阐述了智能体的可追溯性和自我保护动机的其他问题,以及其他奖励篡改问题,例如篡改用户提供的奖励建模反馈、观察篡改和信念篡改。事实证明,所有这些奖励篡改问题及其解决方案可以使用因果影响图自然地表示。
本文最重要的一点是,有一些设计原则可以避免奖励篡改问题,并且这些设计原则是相互兼容的。下一步重要的是将设计原则转变为实用且可扩展的 RL 算法,并验证它们在可能存在各种类型的奖励篡改的设置中做正确的事情。随着时间的推移,我们希望这些设计原则将演变成一套最佳实践,以便构建没有奖励篡改动机的能力强的 RL 智能体。
特别感谢 Damien Boudot 制作这篇文章的图示。

Leave a comment