借助在函数近似器(如树结构的神经网络) 的归纳偏差通过提供结构给规划,使用免模型的强化学习算法进行训练
本文的工作走得更远些, 实验展示了一个完全免模型的方法,没有用到超过标准神经网络组成单元如卷积网络和LSTM等特定结构之外的结构,就可以学到呈现很多典型的基于模型的规划器的特征。
衡量有效性通过下面几种方式:
- 在组合和不可逆的状态空间中的泛化能力
- 数据效率
- 借助额外思考时间的能力
发现智能体有很多期望在一个规划算法中出现的特点。另外,超过当前最优的在极具挑战性的组合领域(如Sokoban)的方法,并比其他的使用强归纳偏差进行规划的免模型方法更好
引言
人工智能的野心是发明出一个牛逼的智能体可以动态适应地产生计划来达成目标。以前这样的角色被基于模型的RL方法统治,首先会学到环境动态或者规则的一个显式模型,然后作用规划算法(比如树搜索)到学到的模型上。基于模型的方法通常更加强大但是学到的模型的规模化受到复杂和高维度环境的影响,尽管已有这个方向上的研究进展。
近期学者提出不同的方法来隐式地学习规划,仅仅通过免模型训练。这些吗免模型规划智能体使用了一个特定的神经网络架构来镜像特定规划算法的结构。例如,神经网络可能会被设计为表示搜索树,前向模拟或者动态规划。其主要思想是,给定合适的对规划的归纳偏差,函数近似器可能学会利用这些结构来学习自身的规划算法。这样的算法函数近似看可能会比显式的基于模型的方法更加灵活,让智能体为特定的环境定制化规划的本质。
本文,我们探索了规划可能会隐式地出现的假设,即使当函数近似器没有针对规划的特定归纳偏差。前人工作已经支持了这个想法,基于模型的行为可以借助规划计算在多个离散步骤上进行均摊使用一般的递归架构学习得到,但是其有效性的深入的展示仍然欠缺。由深度学习成功和神经表示的通用性的启发,我们主要想法是简单地构造一个神经网络有高容量和灵活表示,而不是镜像任何特定的规划结构。给定这样的灵活性,神经网络可能在理论上学习其自身算法来近似规划。特别地,我们使用了一个神经网络的簇基于广泛使用的函数近似架构:堆叠卷积LSTM(ConLSTM)。
纯免模型的强化学习方法能够在看起来需要显式规划的场景中取得成功,我们非常吃惊。这就导出了一个自然的问题:什么是规划?免模型智能体真的可以被看作是在进行规划,而不需要任何显式的环境模型,也不需要任何显式的模型模拟?
实际上,在很多定义中,规划需要一些显式的使用模型考虑,一般是通过考虑可能的使用一个前驱模型来选择一个合适的行动序列未来模拟。这些定义强调了显式向前看的机制的本质,而不是其产生的效果(先见之明 foresight)。然而,什么叫做一个神经网络以一个接近完美的程度模拟了这样的一个规划过程呢?是否规划的一个定义排除了得到的智能体是有效地规划的?
与其将我们的定义被束缚于智能体的内在工作机制,本文我们采取了一个行为主义观点来度量规划为智能体交互的一个性质。特别地,我们考虑了拥有规划能力的智能体的三个关键属性。
第一,一个有效的规划算法应该能够相对简单地泛化到不同的场景下。这里的直觉是,简单的函数近似器将会很难对组合可能性的指数空间预测准确(例如,所有国际象棋位置的值),但是一个规划算法能够执行一个局部搜索来动态计算预测(例如,使用树搜索)。我们使用这个属性来度量过程环境(比如随机网格世界) 有可能 layout 海量组合空间。我们发现免模型的规划智能体达到了当前最优效果,显著地超过了更加专业化免模型规划架构。我们同样调查了超过训练集合中那些问题的更难的问题集合,同样发现我们的架构有效工作——尤其是使用了更大的网络。
第二,一个规划智能体应当能够有效率地从相对少量的数据中学习。基于模型 强化学习方法其实受到了直觉影响,模型(国际象棋的规则)相比直接预测(例如所有棋的位置的值)可以更加有效地学到。我们度量这个属性通过训练免模型规划器在小数据及上,并发现我们的智能体仍然执行得很好,并能够有效地泛化到一个取出的测试集上。
第三,一个有效的规划算法应当能够利用额外的思考时间。简单地说, 算法思考得越多,其性能应该更加好。这个属性可能会在那些不可逆后果到错误决策下尤其重要。我们使用添加额外思考时间在一个片段开头来进行度量,在智能体遵循一个策略采取行动前,并找到我们的免模型规划智能体解决了相对多的问题。
综上,我们的结果表明免模型智能体,没有特定的规划启发的网络架构,可以学会展示很多规划的行为特征。本文给出的这个架构就是为了解释这点,并展示一个简单的方法令人吃惊的力量。我们希望这个发现可以拓宽对更加一般的可以解决更加宽广的规划领域架构的搜索。
2 方法
动机和主要架构介绍。训练设计步骤。
2.1 模型架构
我们希望模型可以表示和学习强大但是未指定的规划过程。不去编码强归纳偏差给特定的规划算法,我们选择了一个高容量的神经网络架构可以表示非常丰富的函数类。如在很多RL工作一样,我们使用了卷积神经网络(能够利用视觉领域的内置空间结构)和LSTMs(有效处理序列问题)。除了这些弱但是常规归纳偏差,我们保持自己架构尽可能的一般和灵活,并给予标准免模型强化学习足够信任来发现规划的功能。
2.1.1 基本架构
本架构的基本单元是一个 ConvLSTM —— 一个类似于 LSTM 的神经网络但是有一个 3D 隐含状态和卷积操作。循环网络 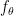






Leave a comment